Последние конференции
- Информационные системы и модели в научных исследованиях, промышленности, образовании и экологии
- Информационные системы и модели в научных исследованиях, промышленности и экологии
- Современные проблемы экологии
- Экологические проблемы окружающей среды, пути и методы их решения
- Экология, образование и здоровый образ жизни
Повышение коэффициентов значимости словосочетаний
С.В. Машанова
Восточно-Сибирский государственный технологический университет,
г. Улан-Удэ
Введение. При решении задачи автоматического реферирования для определения понятий, используемых в тексте, необходимо выделить именные субстантивные словосочетания. На этапе статистического анализа определяются статистические характеристики выделенных словосочетаний. Для повышения коэффициентов значимости словосочетаний необходимо провести анализ полученных словосочетаний.
Постановка задачи. Из исходного текста T выделены словосочетания и сформировано множество Tm= {tmi | i = 1..k′, k′ – количество словосочетаний в тексте}. Каждому словосочетанию соответствуют коэффициенты fi– частота встречаемости tmik в документе; wti – вес tmik.
Необходимо провести анализ выделенных словосочетаний с целью повышения значений коэффициентов.
Разбиение множества словосочетаний на классы эквивалентности. Пусть определено множество лексем L научного текста L = {li | li Î L, i = 1..kl, kl – количество лексем в тексте} с соответствующими им векторами морфологической информации mij, j=1..k, k – количество векторов; сформировано множество словосочетаний Tm= {tmi | i = 1..k′, k′ – количество словосочетаний в тексте}, для поиска которых использованы выделенные лексемы; из словосочетаний множества Tm по признаку общности несущего слова сформированы классы эквивалентности TR = {(tmi , tmj)k | tmi и tmjимеют единое несущее слово; i,j = 1..k′, k′ - количество словосочетаний в тексте, при i≠j; k = 1..kTR, kTR – количество классов эквивалентности}. Каждый класс имеет единое несущее слово, которое входит во все словосочетания класса [1].
Каждый терм описывается векторами tj и qik .
tj =<njt, ijt, wjt, tmj, a j>, (1)
гдеnjt – уникальный номер вектора терма tj;
ijt– индекс терма-словосочетания, идентифицирующий словосочетание в
пределах группы с одинаковым несущим словом;
wjt– несущее слово;
tmj – терм-словосочетание;
aj = < njs, njp, njd, njc > - адрес терма,
njs –номер предложения в документе;
njp – номер параграфа;
njd– номер раздела;
njc– номер главы.
Множество векторов qik описания tmik:
qik =< bti, tmik, fi, wti >, (2)
где bti – несущее слово;
tmik – i-тый терм-словосочетание k-того класса эквивалентности;
fi– частота встречаемости tmik в документе;
wti – вес tmik, который рассчитывается по формуле 3:
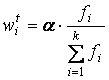 , где
, где 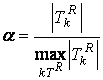 ; (3)
; (3)
|TRk| - суммарная частота встречаемости элементов k-го класса эквивалентности;
k=1..kTR – количество классов эквивалентности.
Анализ выделенных словосочетаний.
Проведем анализ выделенных словосочетаний, который включает три этапа:
- определение и исключение абстрактных прилагательных из словосочетаний;
- выявление композиционных словосочетаний и разделение их на отдельные словосочетания;
- определение синонимов термов и замена термов с низкой частотой встречаемости на соответствующие им синонимы.
Среди выделенных именных субстантивных словосочетаний выполним распознавание лексем, относящихся к абстрактным прилагательным. Для этого сформируем словарь основ абстрактных прилагательных Sa.
Абстрактные прилагательные классифицируются по следующим признакам [3]:
- классификация (любой, каждый, некоторый, определённый, специальный, типичный, общий, частный, единичный, уникальный, сложный, простой, отдельный, особенный и т.д.);
- качество (равный, такой же, тот же самый, похожий);
- количество (максимальный, минимальный, средний);
- логические категории (абсолютный, относительный, положительный, отрицательный, реальный, условный);
- соответствие (правильный, неправильный, точный, приблизительный);
- выгода(выгодный, невыгодный, доходный).
Рассмотрим tmkÎTm − множеству термов-словосочетаний, соответствующие термам лексемы li и вектора морфологической информации mij (i = 1..n, j = 1..k; n – количество лексем, k – количество векторов морфологической информации лексемы li). Если составляющая вектора mij – v1указывает, что часть речи лексемы прилагательное, проверяем лексему li на наличие в словаре Sa.
В словосочетании, содержащем лексему из словаря Sa, исключаем данную лексему и формируем новое множество словосочетаний Tm¢= {tmi¢ | i = 1..kTm, kTm - количество словосочетаний в тексте}. Производим перерасчет значений частоты встречаемости fi и веса термина wti, содержащихся в векторе qik, тех терминов, которые не являются элементами множества Tm ÇTm¢.
Далее из множества словосочетаний Tm¢ текста выделим композиционные (составные) словосочетания. Композиционными словосочетаниями будем называть те словосочетания, которые включают в себя два и более словосочетаний с разными несущими словами, например, словосочетание «экспертная система процедуры управления» содержит словосочетания: «экспертная система», «процедура управления». Разделим такие словосочетания на отдельные словосочетания, включим их в множество Tm¢и произведем перерасчет частоты встречаемости словосочетаний fi и веса термина wti.
Затем найдем множество синонимов C={(c1, c2)i | c1 – синоним; c2 – ссылка на словарную статью, описывающую c1 как термин; i=1¸k, k – количество синонимов} текущего словосочетания в онтологии предметной области O, которой соответствует текст [2]. Осуществим поиск словосочетаний и соответствующих им синонимов во множестве Tm¢, сравним частоты встречаемости этих термов в тексте и произведем замену словосочетаний, имеющих более низкую частоту встречаемости fi, на соответствующие им синонимы с большей частотой встречаемости fj, в связи с этим, частота термина, на который произведена замена, возрастет. На основе выделенных словосочетаний скорректируем построенные классы эквивалентности TR¢. К примеру, класс эквивалентности «система» включает такие термы, являющиеся синонимами, «продукционная система» и «система продукционного типа» с частотами встречаемости 7 и 5 соответственно. Заменим словосочетание «система продукционного типа» на словосочетание «продукционная система», тогда частота встречаемости словосочетания «продукционная система» будет равно 12.
Заключение. Эксперименты показали, что после проведения анализа выделенных словосочетаний частота встречаемости некоторых термов и соответственно их классов эквивалентности значительно повышается.
Список литературы
1. Аюшеева, Н.Н. Исследование и разработка моделей и методов поиска информационных образовательных ресурсов в электронной библиотеке [Текст]: автореф. дис. … канд. техн. наук: защищена 21.01.2005: утв. 10.06.2005 / Н.Н. Аюшеева. – Улан-Удэ, 2005. – 16 с.
2. Найханова Л.В. Технология создания методов автоматического построения онтологий с применением генетического и автоматного программирования: монография [Текст] / Л.В. Найханова. – Улан-Удэ: Изд-во БНЦ СО РАН, 2008. – 244 с.
3. http://ru.wiktionary.org/wiki/Приложение:Классификация_прилагательных