Последние конференции
- Информационные системы и модели в научных исследованиях, промышленности, образовании и экологии
- Информационные системы и модели в научных исследованиях, промышленности и экологии
- Современные проблемы экологии
- Экологические проблемы окружающей среды, пути и методы их решения
- Экология, образование и здоровый образ жизни
Управление изменениями программного кода стороннего производителя с помощью конфигурационного управления программного обеспечения, основанного на потоках
А.В. Юрченко
ЗАО «ЕС-лизинг»,
г. Москва
В настоящее время становится довольно распространенной практика изменения, или расширения программного кода, написанного сторонним производителем, особенно с повсеместным распространением программного обеспечения с открытым исходным кодом. Сборка на основе существующего кода третьих лиц увеличивает время готовности собственного продукта. Сторонний производитель обычно часто выпускает заплаты и новые свойства в виде релизов. Управление процессом объединения релизов стороннего производителя со своими изменениями требует дополнительного уровня конфигурационного управления (КУ). Традиционные инструменты (программные продукты) КУ программного обеспечения (ПО), основанные на ветвлении, требуют организации излишних процессов ветвления и слияния. В данной работе описано, как КУ ПО, основанное на потоках (stream), обеспечивает более интуитивную и эффективную модель параллельной разработки для управления изменениями в программном коде стороннего производителя.
Управление изменениями кода стороннего производителя требует дополнительного уровня КУ для интеграции последующих релизов стороннего производителя. Код стороннего производителя должен быть импортирован, выполнено его слияние с предыдущими релизами, слияние с заданным набором своих собственных изменений, и, в итоге, слияние с одним или более потоками кода. Трудность и задача заключаются в том, чтобы независимо сопровождать код стороннего производителя и управлять выборочными слияниями и релизами своих пользовательских свойств вместе с обновлениями стороннего производителя, при этом, не подвергая опасности и не разрушая активных потоков кода.
Традиционные модели КУ ПО, основанные на ветвлении, используют огромное количество ветвей для параллельного сопровождения исходного кода стороннего производителя и своих модификаций этого кода. В типичной модели ветвления главный поток представляет центральный поток кода разработки. Ветвь кода стороннего производителя ответвляется от главного потока для изоляции и сопровождения кода стороннего производителя. Свойства ответвляются от главного потока для изоляции своих собственных, пользовательских разработок. Релизы ответвляются от главного потока для изоляции своих собственных релизов. В результате, требуется строгая координация операций слияния от ветви к ветви, чтобы передавать изменения между различными комбинациями ветвей без нарушения их целостности.
Диаграмма на рисунке 1 показывает модель ветвления для процесса сопровождения пользовательского релиза, основанного на коде стороннего производителя, в новом проекте. В данном примере проект начинается с импорта кода стороннего производителя версии «6.0» в главный поток. Код стороннего производителя сопровождается независимо в отдельной ветви стороннего производителя (метка «a»). Пользовательские свойства разрабатываются в выделенных ветвях свойств (метка «b») и в итоге объединяются с главным потоком (метка «c»). Ветвь пользовательского релиза версии «1.0» (метка «d») используется для подготовки релиза (т.е. настройки среды функционирования, подготовки заплат, проведения официального тестирования), обеспечивает изоляцию для специфических настроек релиза, пометки версий–кандидатов для релиза (на рисунке – «КР»), а так же позволяет производить непрерывное слияние будущих параллельных доработок релиза с главным потоком. Когда пользовательский релиз протестирован до уровня готовности, он помечается как «1.0» и объединяется с главным потоком (метка «e»). Ветвь пользовательского релиза «1.0» так же позволяет сопровождать оба пользовательских свойства, основанных на версии «6.0» кода стороннего производителя, независимо от исходного кода стороннего производителя, изолированного в ветви стороннего производителя.
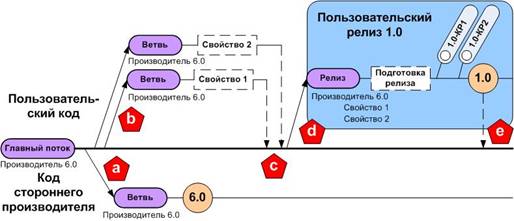
Рис. 1. Традиционная модель ветвления для пользовательского релиза «1.0», основанного на коде стороннего производителя
Диаграмма на рисунке 2 является продолжением предыдущей модели ветвления, показывая обновление кода стороннего производителя, заплату, и новый пользовательский релиз. Обновление кода стороннего производителя требует импорта и объединения релиза «6.1» от стороннего производителя с ветвью стороннего производителя (метка «f»). Специально для слияния обновленного кода стороннего производителя с главным потоком, в котором содержатся все пользовательские изменения, создается отдельная ветвь (метка «g»). Такая отдельная ветвь изолирует главный поток от любых проблем слияния таких, как несовместимость с новым пользовательским свойством, или конфликтные ситуации с пространством имен файлов (например, новый файл производителя может иметь то же самое имя, что и новый пользовательский файл в том же каталоге). Когда объединение прошло успешно, ветвь слияния с кодом стороннего производителя сама объединяется с главным потоком (метка «h»). Затем создается ветвь пользовательского релиза для подготовки к выпуску релиза «2.0» (метка «m»).
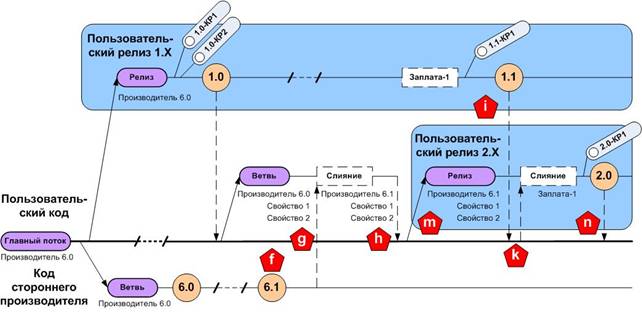
Рис. 2. Традиционная модель ветвления для пользовательского релиза «2.0», основанного на коде стороннего производителя
В то же самое время для пользовательского релиза «1.0» создается заплата для дефекта, что выливается в создание релиза «1.1» (метка «i»). Эта заплата так же объединяется сначала с главным потоком, а, затем, с ветвью пользовательского релиза «2.0», чтобы предотвратить возвращение к предыдущей версии (метка «k»). После подготовки и пометки пользовательского релиза версии «2.0», все изменения объединяются с главным потоком (метка «n»). Ветвь пользовательского релиза версии «2.0» сопровождает два (предыдущих) пользовательских свойства и новую заплату и все это интегрировано с недавно обновленным кодом стороннего производителя версии «6.1».
Стоит дать одно пояснение по поводу обновления кода стороннего производителя на рисунке 2. Все пользовательские свойства, присутствующие в главном потоке, объединяются с кодом стороннего производителя версии «6.1» в ветви объединения с кодом стороннего производителя (метка «g»). Если интегрировать только часть свойств с обновлениями стороннего производителя, то пользовательские свойства распределятся по ветвям дерева версий проекта. Это недопустимо, поскольку главный поток должен оставаться центральным потоком кода разработки. Возвращаясь назад, рисунок 3 показывает весьма нежелательную модель ветвления для поддержки релизов, основанных на обновлениях стороннего производителя и свойствах пользователя. Чтобы объединить выбранные свойства с обновлениями стороннего производителя, от ветви стороннего производителя создается ветвь пользовательского релиза (метка «p»), и объединяется с ветвью выбранного свойства (метка «r»). В данном примере свойство-2 и заплата-1 объединяются с ветвью релиза, но не свойство-1. Это идет вразрез с политиками и лучшими практиками КУ ПО представления о главном потоке, который должен представлять собой центральный поток разработки, и вызывает децентрализацию ветвей релизов. Создание пользовательских ветвей релизов одновременно от главного потока и от ветви стороннего производителя очень быстро создает ненужную, сложную сеть ветвлений и слияний.
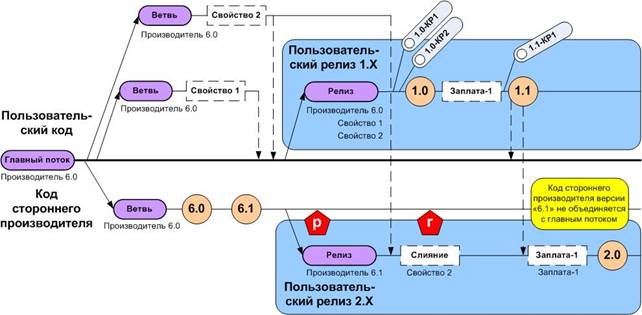
Рис. 3. Традиционная модель ветвления для управления обновлениями свойств кода стороннего производителя
Если полагаться на ветвь ориентированные модели КУ ПО для управления изменениями релизов стороннего производителя, то это потребует сложного процесса управления операциями слияния между бесчисленным количеством ветвей. Приведенный пример показывает только два пользовательских релиза, одну заплату и одно обновление производителя. Ситуация стремительно становится чрезвычайной когда приходится иметь дело с множеством обновлений производителя и множеством пользовательских релизов. Дополнительная сложность возникает, когда необходимо передавать заплаты между главным потоком и ветвями свойств, ветвями слияния стороннего производителя, ветвями релизов пользователя, или между всеми сразу. Из этого примера можно сделать вывод, что традиционные решения, основанные на ветвлении, быстро становятся громоздкими и трудно управляемыми.
Если добавить возможность автоматического наследования изменений между соседними ветвями, то процесс разработки ПО можно рассматривать в терминах потоков (streams). Архитектура КУ ПО, основанная на потоках, интуитивно моделирует процесс параллельной разработки с помощью независимых, настраиваемых процессов, которые делают операцию слияния проще, благодаря автоматическому наследованию изменений.
Потоки можно рассматривать как ветви, каждая из которых представляет специфическую конфигурацию исходного кода. Более детально, поток содержит конкретную версию каждого файла, который в нем находится. Когда разработчикам требуется изменить код, они создают поток рабочей области из любого другого потока, и тут же получают доступ ко всем файлам для конкретной конфигурации. Подобным же образом, когда код необходимо развернуть, он извлекается из потока в локальный каталог.
Потоки организованы в родительско-дочернюю иерархию, которая называется иерархией потоков. Иерархия потоков представляет собой дерево потоков, которая определяет технологический процесс разработки ПО. Каждый поток в технологическом процессе представляет отдельный этап процесса, такой, как разработка, интеграция, тестирование качества, аудит. Изменения продвигаются по иерархии. Чтобы контролировать продвижение, потоки могут быть заблокированы пользователем, или ролью. Например, только члены группы выпуска релизов могут перемещать код в/из потока тестирования. Потоки так же имеют уникальную встроенную функцию, которая позволяет конфигурациям автоматически наследоваться вниз по всей иерархии от родительских элементов к дочерним. Наследование позволяет более новым версиям файлов, выше в иерархии, становиться автоматически доступными (для обновления) ниже по иерархии. Например, исправление дефекта в потоке тестирования и соответствующая заплата автоматически доступны всем 50 потокам разработчиков где угодно ниже по иерархии.
Диаграмма на рисунке 4 показывает иерархию потоков, которая моделирует параллельную разработку пользовательских свойств на основе кода стороннего производителя. Код стороннего производителя импортируется и независимо управляется в базовом потоке «Производитель». Моментальные (snapshot) потоки (представляют мгновенный срез – снимок – файлов из другого источника в какой-либо момент времени) отходят от основного потока и представляют собой неизменяемые области, которые фиксируют конфигурацию каждого релиза стороннего производителя (метка «a») и служат как стабильные именованные основания для конкретных версий пользовательских потоков кода разработки (метка «b»). Каждый поток кода разработки в данном примере создает рабочие потоки, названные «интеграция», «тест» и «пользователь», соответствующие модели процесса разработки (метка «c»). Разработка каждой новой версии происходит в рабочих потоках. Версия продвигается через этапы интеграции и тестирования (метка «с»). В итоге, изменения проходят до пользовательского потока (т.е. конечного продукта), где создается моментальный (snapshot) поток, обозначающий официальный пользовательский релиз (метка «d»). Квадрат с древовидной иерархией под потоками обозначает, что сделанные изменения наследуются дальше по структуре. Квадрат с замком обозначает, что изменения в потоке контролируются пользователем, или группой. Сравнивая с моделью ветвления, модель, основанная на потоках, представляет собой более естественную организацию релизов стороннего производителя, релизов пользователя, и рабочих процессов пользователя.
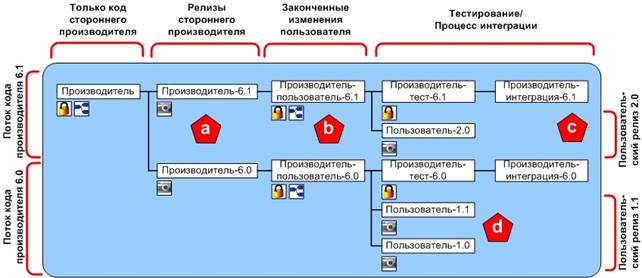
Рис. 4. Обзор модели потоков для релизов пользователя, основанных на коде стороннего производителя
Начиная новый проект, основанный на коде стороннего производителя, необходимо импортировать код стороннего производителя, создать моментальный поток релиза стороннего производителя, и создать поток кода разработки с помощью потоков. Диаграмма на рисунке 5 представляет собой структуру потоков для нового проекта, в котором сопровождается код стороннего производителя и создаются пользовательские релизы. Исходный код производителя версии «6.0» импортируется в базовый поток из рабочего потока, и создается моментальный поток релиза стороннего производителя (метка «a»). Этот моментальный поток служит в качестве стабильного основания для пользовательского потока кода разработки, основанного на версии «6.0». Пользовательские свойства разрабатываются в рабочих потоках и постепенно переходят в соответствующие потоки свойств (метка «b»). Индивидуальные потоки свойств помогают совместной разработке между членами команды, а так же могут использоваться для тестирования на приемлемость этих свойств для клиента. По мере того, как свойства развиваются, их изменения переносятся в область интеграции, чтобы их можно было объединить с другими свойствами (метка «c»). Свойства можно переносить для интеграции только когда они полностью (или хотя бы частично) завершены. Частота переносов прямо пропорциональна уровню непрерывной интеграции, поскольку переданные изменения сразу же наследуются другими разработчиками на нижних потоках. Наследование является инструментом облегчения слияния, поскольку у разработчиков появляется возможность выбрать интеграцию с другими (завершенными) свойствами до того, как их собственная работа выполнена. После т.н. «дымового» тестирования и интеграции, изменения передаются на тестирование качества и предметное регрессионное тестирование «черного ящика» (метка «c»). Опционально, неизменные моментальные потоки могут создаваться и отходить от потоков тестирования, чтобы обозначить протестированную конфигурацию, обеспечивающую 100 % прохождение тестов. Когда тестирование завершено и запущен процесс создания релиза, изменения передаются в создаваемый пользовательский (т.е. производственный) моментальный поток, в котором фиксируется релиз 1.0 (метка «d»). Таким образом, иерархия потоков организовала код стороннего производителя независимо от пользовательского релиза и обеспечила интуитивный рабочий процесс для разработки, тестирования, и релизов.
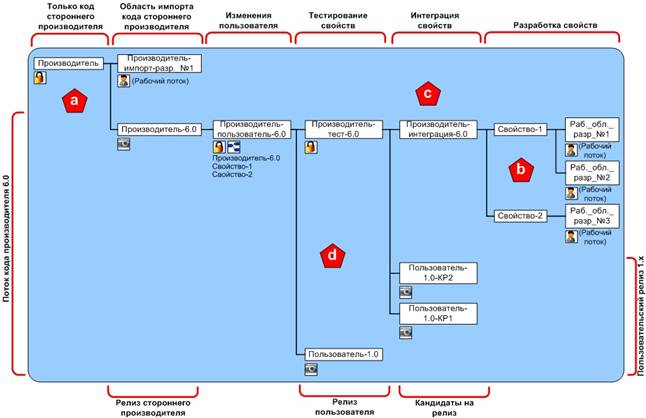
Рис. 5. Модель потоков для пользовательского релиза «1.0», основанного на коде стороннего производителя
Достоинства модели потоков становятся очевидными сразу после первого обновления стороннего производителя. Рисунок 6 является продолжением предыдущей структуры потоков, выделяющий обновления стороннего производителя, новый пользовательский релиз и объединение свойств. Обновленный исходный код стороннего производителя версии «6.1» импортируется из рабочего потока и объединяется с базовым потоком, создается моментальный поток релиза версии «6.1» (метка «f»). Этот моментальный поток служит в качестве стабильного основания для пользовательского потока кода разработки, основанного на версии «6.1». Тем временем, параллельно разрабатывается пользовательская заплата для потока кода, основанного на версии «6.0», далее она фиксируется в пользовательском релизе «1.1» (метка «i»). Далее происходит миграция пользовательских изменений в поток кода разработки «6.1». До этого момента все протестированные релизы версий «1.х» располагаются в пользовательском потоке «6.0». В данном примере свойство-2 и заплата-1 переносятся в рабочий поток (метка «h»). Во время переноса свойства объединяются с кодом стороннего производителя «6.1» и тестируются на совместимость (метка «k»).
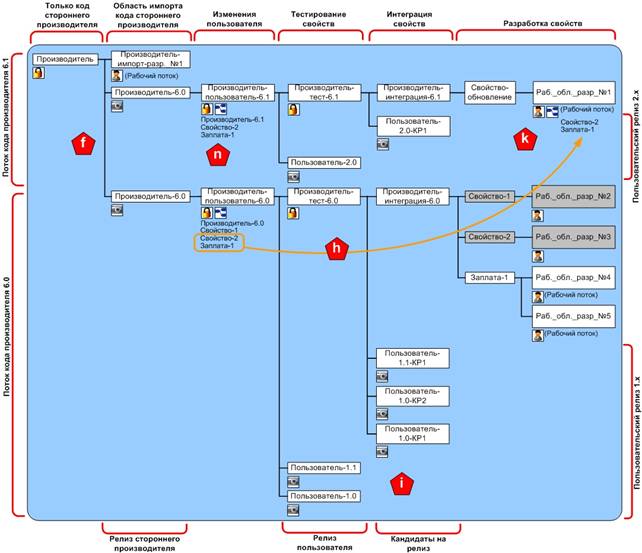
Рис. 6. Модель потоков для пользовательского релиза «2.0», основанного на коде стороннего производителя
Когда слияние выполнено успешно, вся работе в итоге переносится в версию «6.1» интеграции, тестирования и пользовательских изменений (метка «n»). Создается пользовательский моментальный поток релиза «2.0», в котором фиксируются свойство и заплата и код стороннего производителя версии «6.1». После удаления неиспользуемых потоков финальная структура потоков будет выглядеть, как показано на рисунке 7, моделируя два обновления стороннего производителя и три пользовательских релиза.
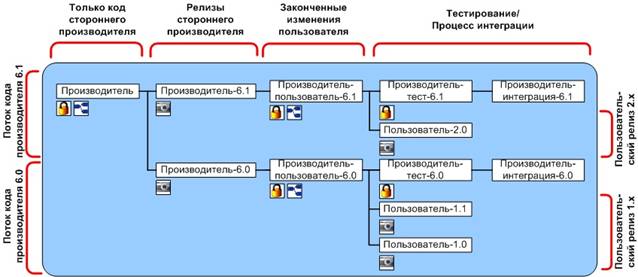
Рис. 7. Конечная модель потоков организации двух обновлений стороннего производителя и трех пользовательских релизов
Управление пользовательскими изменениями, основанными на коде стороннего производителя, требует дополнительного уровня КУ для сопровождения обновлений стороннего производителя вместе с пользовательскими релизами. Чтобы успешно управлять таким процессом, код стороннего производителя должен сопровождаться независимо от целевых потоков кода, в которых разрабатываются собственные релизы. Задача состоит в том, чтобы независимо сопровождать код стороннего производителя и интегрировать обновления стороннего производителя с выбранными собственными изменениями, при этом сохраняя целостность активных потоков кода разработки. Модель, основанная на ветвлении, создает многочисленные ветви и требует сложного управления операциями слияния. Модель, основанная на потоках, предоставляет более понятное решение, используя параллельные потоки кода, наследование потоков, слияние свойств и рабочие потоки. В общем случае, качество ПО улучшается, начиная с процесса разработки, и заканчивая тестированием и выпуском релиза. Потоковая модель обеспечивает создание технологических процессов, которые моделируют естественное развитие ПО от разработки до релиза. По сравнению с традиционным ветвлением, потоки в приведенных примерах в данной работе обеспечивают более естественный способ управления изменениями кода стороннего производителя.
Глоссарий
Версия (Version) – уникальное состояние программного обеспечения.
Ветвление (Branching) – в дисциплине конфигурационного управления программного обеспечения представляет собой контролируемое дублирование объектов (таких, как файл исходного кода, или дерево каталогов) таким образом, чтобы модификации могли происходить параллельно в обеих ветвях.
Главный поток (Mainline) – поток программного кода, от которого отходят и к которому присоединяются второстепенные потоки кода.
Заплата (Patch) – отдельная программа, разработанная для решения проблем в основной программе.
Конфигурационное управление программного обеспечения (Softwareconfigurationmanagement) – дисциплина отслеживания и управления изменениями в программном обеспечении.
Поток Кода (Codeline) – множество логических изменений, связанных между собой и выполняемых в течение промежутка времени для файла, группы файлов, либо для всего программного проекта в целом.
Развертывание (Deployment) – любые действия, которые делают программную систему доступной для использования.
Релиз (выпуск) (SoftwareRelease) – поставка (выпуск) программного кода, документации, материалов для сопровождения.
Сборка (SoftwareBuild) – представляет собой процесс преобразования файлов с исходным программным кодом в отдельные программные артефакты, которые могут быть выполнены на компьютере. Обычно представляет собой процесс т.н. компиляции, который преобразует файлы исходного кода в исполнимый код.
Свойство (Feature) – различимые характеристики программных элементов.
Слияние, объединение (Merging) (так же называется интеграцией) – операция, которая согласовывает множество изменений, сделанных для разных версий одних и тех же файлов. Необходима, когда версии файла менялись разными людьми в одно и тоже время.
Сторонний производитель (Vendor) – обозначает любого, кто обеспечивает компанию товарами, или услугами.
Списоклитературы
1. Book. Software Configuration Management Patterns. Berczuk, Appleton. ISBN: 0201741172
2. CVS. http://ximbiot.com/cvs/manual/cvs-1.11.22/cvs_13.html#SEC103
3. SVN. http://svnbook.red-bean.com/en/1.1/ch07s05.html
4. Perforce. http://www.perforce.com/perforce/technotes/note015.html