Последние конференции
- Информационные системы и модели в научных исследованиях, промышленности, образовании и экологии
- Информационные системы и модели в научных исследованиях, промышленности и экологии
- Современные проблемы экологии
- Экологические проблемы окружающей среды, пути и методы их решения
- Экология, образование и здоровый образ жизни
Модификация численного метода крупных частиц для решения ресурсоемких задач газо- и гидродинамики для использования на высокопроизводительных вычислительных системах, использующих технологию MPI
И.А. Разуваев
Тульский государственный университет, кафедра «Ракетное вооружение»,
г. Тула
Решение трехмерных задач газовой и гидродинамики является неотъемлемым этапом проектирования летательных аппаратов различного назначения, в автомобилестроении, а так же в строительстве и т. д. При этом главной проблемой таких численных расчетов всегда являлась чрезвычайная требовательность вычислительного алгоритма к основным ресурсам ЭВМ — объёму памяти и скорости выполнения инструкций центральным процессором. Зачастую на один расчет существующими методами с выбранными параметрами течения газа или жидкости в сложной, высокодискретизированной расчетной области требуется машинное время одной ЭВМ исчисляемое в сутках. Данный факт приводит к появлению значительных временных простоев в процессе проектирования. При этом если объем памяти не представляет настолько большой проблемы, то скорость исполнения команд процессором хоть сколько-нибудь значимо поднять невозможно. Более того, технологически развитие ЦПУ на данном этапе времени сильно заторможено. Единственным актуальным путем сокращения машинного времени вычисления в этих условиях является использование параллельных распределенных вычислений.
В данной статье затронут вопрос модификации классического метода крупных частиц и его параллельных вариаций с целью программной реализации на высокопроизводительной вычислительной системе с использованием технологии MPI, а также оценены машинно-временные показатели прироста производительности вычислений. Описываемый метод разрабатывался из условия, что узлы системы построены на базе 64-хбитных, минимум двуядерных, процессоров. Это условие продиктовано возможностью развертывания бюджетного вычислительного MPI-кластера в обычном вычислительном зале вуза.
Классический алгоритм метода крупных частиц предусматривает последовательное прохождение по всем ячейкам исходной расчетной области на эйлеровом этапе, а затем на лагранжевом и заключительном этапах. После чего расчет начинается на новом временном слое. Однако, тот факт, что данный метод является конечно-разностным, позволяет производить расчеты отдельных подобластей параллельно друг другу. На этом основан один из самых распространенных и применяемых методов распараллеливания алгоритма метода крупных частиц. Однако тот же факт с учетом того, что компьютеры вычислительной системы имеют одинаковые или почти сопоставимые по характеристикам процессоры, позволяет использовать иной подход к распараллеливанию.
MPI-система настраивается так, что на каждом узле системы должно быть запущено по одному параллельному процессу, в распоряжение которому отдано два ядра. Компьютеры с 4-хядерными процессорами должны интерпретироваться внутри кластера как два двуядерных узла и т. д.
Распараллеливание включает в себя два этапа: макроэтап и микроэтап. На микроэтапе рассматривается только один процесс в изоляции от других. На этом этапе распараллеливание основывается на том, что лагранжев и заключительный этапы в сумме требуют больше машинного времени, чем эйлеров. Если упорядочить нумерацию ячеек так, чтобы эти ячейки укладывались в пространственные плоские слои, то становится возможным построить карту слоев и пронумеровать эти слои. Учитывая, что для расчета ячейки на лагранжевом и заключительном этапах требуется знать эйлеровы значения в ячейках текущего, предыдущего и следующего пространственных слоев, можно сделать вывод о том, что вычисления лагранжева и заключительного этапа можно начинать отдельным потоком сразу после того, как будут вычислены эйлеровы значения на первых двух пространственных слоях расчетной области. При этом идентификаторы вычисляемых пространственных слоев на эйлеровом этапе всегда старше идентификаторов слоев, используемых в данный момент времени на последующих этапах, что способствует упрощению планирования доступа потоков к памяти и избавляет от необходимости ввода в код дополнительных системных инструкций.
Главной особенностью рассматриваемого метода является макроэтап, на котором расчеты нового временного слоя начинаются сразу же после того, как полностью вычисляются первые два пространственных слоя на заключительном этапе. При этом данная задача поручается соседнему процессу вычислительного кластера, что приводит к необходимости пересылки вычисленных значений по сети. В свою очередь запущенный процесс вычисления нового временного слоя также порождает запуск нового процесса по достижению указанного условия.
Для количественной оценки показателей прироста производительности и ускорения вычислений, получаемого с применением данного метода, примем следующие обозначения:
· ![]() — время, требуемое на расчет одного пространственного слоя на эйлеровом этапе;
— время, требуемое на расчет одного пространственного слоя на эйлеровом этапе;
· ![]() — время, требуемое на расчет одного пространственного слоя на лагранжевом и заключительном этапах;
— время, требуемое на расчет одного пространственного слоя на лагранжевом и заключительном этапах;
· ![]() — число пространственных слоев расчетной области;
— число пространственных слоев расчетной области;
· 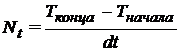 — требуемое число шагов расчета по времени;
— требуемое число шагов расчета по времени;
· ![]() — число двуядерных узлов вычислительного кластера.
— число двуядерных узлов вычислительного кластера.
Следуя классической схеме вычислений, общее машинное время, требующееся для расчета исходной области можно вычислить по зависимости
|
|
(1) |
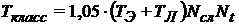 .
. Эмпирический коэффициент 1,05 учитывает возможные потери времени на выполнение сторонних системных и сопутствующих вычислению инструкций и команд, не имеющих прямого отношения к вычислению значений в ячейках расчетной области.
При использовании метода разделения расчетной области машинное время системы из ![]() узлов определяется следующим образом:
узлов определяется следующим образом:
|
|
(2) |
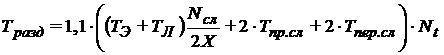 ,
, где 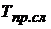 — время, затрачиваемое на передачу параметров одного слоя от процесса процессу,
— время, затрачиваемое на передачу параметров одного слоя от процесса процессу, ![]() — время, затрачиваемое на прием параметров одного слоя от какого-либо процесса.
— время, затрачиваемое на прием параметров одного слоя от какого-либо процесса.
Эмпирический коэффициент 1,1 учитывает уже вышеуказанные потери, а также возможные задержки при пересылке сообщений по сети. Нетрудно также заметить, что время пересылки и приема слоя процессом в общем случае одинаково и зависит в большей степени от объема пересылаемых данных.
Таким образом
|
|
(3) |
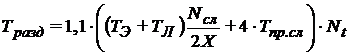 .
. Определим теперь машинно-временные характеристики рассматриваемого модифицированного метода вычислений. Схематично загрузку процессов работой можно проиллюстрировать следующей схемой:
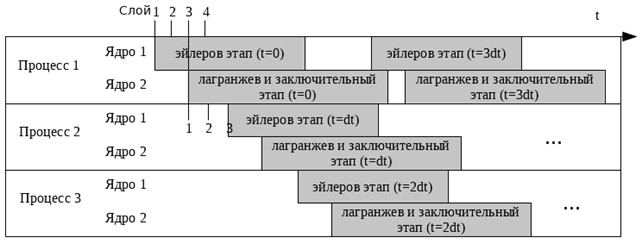
Рис. 1.Схема загрузки узлов кластера
Исходя из этого, можно определить машинное время расчета одним процессом одного временного слоя:
|
|
(4) |
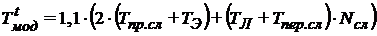 .
. Для данного выражения также справедливо утверждение о том, что 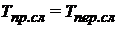 . Тогда полное время расчета определится по зависимости
. Тогда полное время расчета определится по зависимости
|
|
(5) |
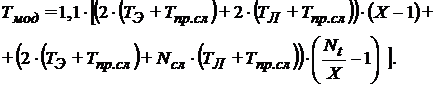
Введем следующие коэффициенты, выражающие отношение машинного времени, требуемого для различных операций ко времени выполнения эйлерова этапа:
|
|
(6) |
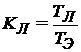 ;
; 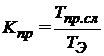 .
. Тогда для вычисления выгоды при использовании каждого из модифицированных методов определим целевые функции, показывающие отношение общего машинного времени при использовании соответствующих методов ко времени, требующемуся при использовании классического метода.
Учитывая (1), (3) и (6), получаем:
|
|
(7) |
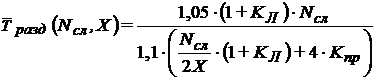
А с учетом (1), (5) и (6), получаем:
|
|
(8) |
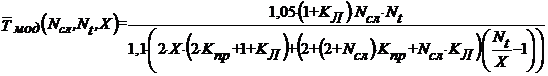
Величина коэффициента ![]() в критической степени зависит от текста программы, используемого компилятора и используемых ключей компиляции. В тестовых условиях при использовании компилятора C++ из семейства GCC 4.4.4 с ключами оптимизации -O2 -mtune=core2 и выключении отладочной информации получено среднее значение
в критической степени зависит от текста программы, используемого компилятора и используемых ключей компиляции. В тестовых условиях при использовании компилятора C++ из семейства GCC 4.4.4 с ключами оптимизации -O2 -mtune=core2 и выключении отладочной информации получено среднее значение ![]() .
.
В свою очередь значение коэффициента ![]() в большей степени зависит от объема пересылаемых данных, от скорости сетевого соединения, от загрузки ЛВС вычислительной системы и от особенностей реализации промежуточного ПО кластера, нежели от явных действий программиста. Значение этого коэффициента в исследовательских целях в данном случае примем лежащим в диапазоне
в большей степени зависит от объема пересылаемых данных, от скорости сетевого соединения, от загрузки ЛВС вычислительной системы и от особенностей реализации промежуточного ПО кластера, нежели от явных действий программиста. Значение этого коэффициента в исследовательских целях в данном случае примем лежащим в диапазоне ![]() .
.
Изучая функцию (8), можно заметить, что ее значение зависит от общего числа шагов по времени ![]() . В общем случае это значение всегда весьма велико, и в исследовательских целях для дальнейших выводов будем использовать значения в диапазоне
. В общем случае это значение всегда весьма велико, и в исследовательских целях для дальнейших выводов будем использовать значения в диапазоне ![]() .
.
С учетом вышесказанного нетрудно определить сравнительные характеристики описываемого метода относительно известных ранее методов.
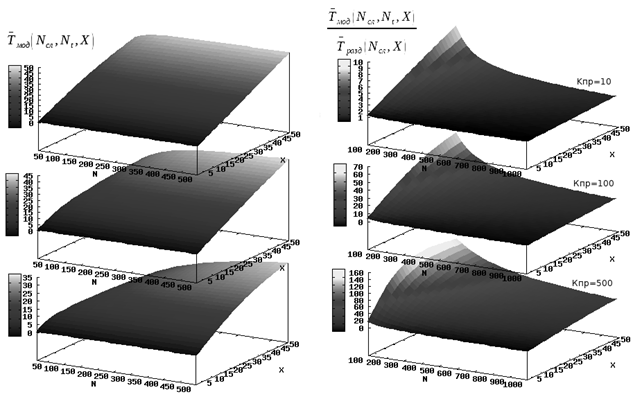
Рис. 2. Сравнительная характеристика методов
Из приведенных выше графиков можно сделать вывод, что модифицированный метод выгодно использовать при наличии в вычислительной системе не менее 20 двуядерных узлов. При этом достигается увеличение производительности вычислений в не самых оптимальных режимах от 2,5 — 3 раз относительно метода разделения расчетной области и от 18 — 19 относительно классической последовательной реализации. В целом показатели производительности описанного алгоритма тем выше, чем выше число узлов вычислительной системы.
Следует заметить, что при таких параметрах ЛВС и таких расчетных параметрах, когда время пересылки данных намного превышает время их обработки (высокая грануляция вычислительного алгоритма), использование параллельных методов на данной архитектуре кластера себя не оправдывает, что изначально и отмечается как особенность систем данного типа.
Список литературы
1. Белоцерковский О.М., Давыдов Ю.М. Метод крупных частиц в газовой динамике, М.: Наука, 1982.—312 с.
2. http://parallel.ru.