Последние конференции
- Информационные системы и модели в научных исследованиях, промышленности, образовании и экологии
- Информационные системы и модели в научных исследованиях, промышленности и экологии
- Современные проблемы экологии
- Экологические проблемы окружающей среды, пути и методы их решения
- Экология, образование и здоровый образ жизни
Программно-аппаратный комплекс параллельных вычислений внутри локальной вычислительной сети организации для решения ресурсоемких задач газовой и гидродинамики
И.А. Разуваев, Ю.В. Слепцов
Тульский государственный университет,
Управление информационных технологий и автоматизации,
г. Тула
Достигнутые ограничения в тактовой частоте центральных процессоров и одновременное усложнение вычислительных задач привели к распространению параллельных и распределённых вычислений с использованием многоядерных процессоров и многопроцессорных систем. Системы параллельных вычислений профессионального уровня представлены в полной мере на рынке, однако их высокая стоимость не позволяет закупать и использовать их повсеместно в вузах и соответствующих профильных организациях. Однако, задачи распараллеливания не являются тривиальными и требуют как обучения программистов вычислительной системы, так и проведение НИР в области разработки эффективных параллельных алгоритмов.
Цель создания описываемой в данной статье системы — предоставление возможностей создания и использования высокопроизводительных компьютерных программ с применением технологий распределённых и параллельных вычислений в стандартных компьютерных классах, вычислительных залах и аудиториях, оборудованных группой настольных компьютеров, соединённых локальной вычислительной сетью Ethernet со скоростью передачи данных 100 или 1000 Мбит/с.
Аппаратная часть рассматриваемого комплекса представляет собой группу рабочих станций, объединенных в локальную вычислительную сеть. Главное требование к используемым модулям — применение процессоров, способных выполнять один и тот же набор инструкций (наиболее целесообразно использовать процессоры с поддержкой набора команд x86-64, MMX, SSE, SSE2, SSE3). Данное требование обусловлено необходимостью обеспечения выполнения одной программы, на всех узлах кластера одновременно. В целом, такой подход позволяет получить работоспособный суперкомпьютер в уже имеющейся IT-инфраструктуре без дополнительных затрат на специализированное оборудование.
Использование технологии Ethernet в качестве канала связи между узлами рассматриваемого ПАК накладывает существенное ограничение на скорость обмена данными, однако, минимизирует вложения в инфраструктуру. При этом предпочтительным является использование соединения 1000BASE Gigabit Ethernet (средняя задержка 5·10-5 с, максимальная скорость передачи данных 125 Мб/с). Допускается использование соединения 100BASE Fast Ethernet (средняя задержка 8·10-5 с, максимальная скорость передачи данных 12,5 Мб/с). Использование менее скоростных типов соединения нецелесообразно, так как значительно снижает реальную производительность кластера. Приведенные значения могут явно использоваться при выявлении параллелизма решаемой задачи для оценки машинно-временных характеристик алгоритмов.
В качестве системного программного обеспечения выбраны операционные системы (ОС) на базе ядра Linux. Данные системы обладают следующими свойствами:
· полная поддержка целевого оборудования;
· поддержка многозадачности;
· разделение и управление правами доступа пользователей;
· наличие бесплатных дистрибутивов с широким набором программного обеспечения;
· не требуют антивирусного ПО, что приводит к общему повышению производительности;
· возможность тонкой настройки для дополнительного повышения производительности.
Использование ОС семейства Windows также возможно, однако требует значительных затрат на приобретение лицензий на ОС и сопутствующее ПО для каждого вычислительного модуля. Реальная пиковая производительность системы на базе ядра Linux превышает аналогичный показатель, измеренный на Windows-кластере, на 1 % — 5 %.
В качестве промежуточного программного обеспечения использована MPICH2, реализующая технологию MPI (Message Passing Interface), являющаяся на сегодняшний день самой распространённой из всех технологий параллельного программирования для кластеров. Смысл технологии заключается в том, что обмен данными между параллельно выполняющимися блоками программы происходит при помощи сообщений. Под сообщением подразумевается передача или приём как инструкций, так и данных. Допустимы как обмены типа точка-точка, так и коллективные обмены данными.
Основной сложностью при использовании MPI является мышление в «невычислительных» терминах. То есть процесс программирования с применением MPI является в достаточной степени низкоуровневым, и программист обязан принимать во внимание топологию процессов и, в некоторых случаях, аппаратную конфигурацию вычислительной системы. Однако такой подход позволяет получить очень высокие показатели производительности при должном уровне оптимизации программы.
Для оценки показателей описанной системы рассмотрим сравнение машинно-временных характеристик алгоритма классического метода крупных частиц в задачах газовой и гидродинамики с характеристиками его базового параллельного аналога, использующего подход разделения исходной области на подобласти. Примем следующие обозначения:
· ![]() — время, требуемое на расчет одного пространственного слоя на эйлеровом этапе;
— время, требуемое на расчет одного пространственного слоя на эйлеровом этапе;
· ![]() — время, требуемое на расчет одного пространственного слоя на лагранжевом и заключительном этапах;
— время, требуемое на расчет одного пространственного слоя на лагранжевом и заключительном этапах;
· ![]() — число пространственных слоев расчетной области;
— число пространственных слоев расчетной области;
· 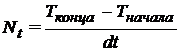 — требуемое число шагов расчета по времени;
— требуемое число шагов расчета по времени;
· ![]() — число узлов вычислительного кластера.
— число узлов вычислительного кластера.
Следуя классической схеме вычислений, общее машинное время, требующееся для расчета исходной области можно вычислить по зависимости
|
|
(1) |
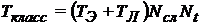 .
. При использовании метода разделения расчетной области машинное время системы из ![]() узлов определяется следующим образом:
узлов определяется следующим образом:
|
|
(2) |
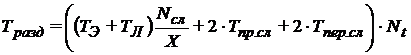 ,
, где ![]() — время, затрачиваемое на передачу параметров одного слоя от процесса процессу,
— время, затрачиваемое на передачу параметров одного слоя от процесса процессу, ![]() — время, затрачиваемое на прием параметров одного слоя от какого-либо процесса. Нетрудно заметить, что время пересылки и приема слоя процессом в общем случае одинаково и зависит в большей степени от объема пересылаемых данных.
— время, затрачиваемое на прием параметров одного слоя от какого-либо процесса. Нетрудно заметить, что время пересылки и приема слоя процессом в общем случае одинаково и зависит в большей степени от объема пересылаемых данных.
Таким образом,
|
|
(3) |
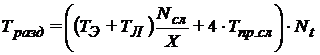 .
. Введем следующие коэффициенты, выражающие отношение машинного времени, требуемого для различных операций ко времени выполнения эйлерова этапа:
|
|
(4) |
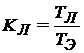 ;
; 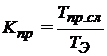 .
. Тогда для вычисления прироста производительности при использовании описываемого программно-аппаратного комплекса определим целевую функцию, показывающие отношение машинного времени, необходимого для выполнения параллельного алгоритма, ко времени, необходимому для выполнения последовательного.
|
|
(5) |
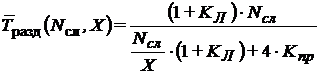
Значение коэффициента ![]() в большой степени зависит от объема пересылаемых данных, от скорости сетевого соединения, от загрузки ЛВС вычислительной системы и от особенностей реализации промежуточного ПО кластера и может быть для оценочных расчетов принято находящимся в диапазоне от 1 до 50.
в большой степени зависит от объема пересылаемых данных, от скорости сетевого соединения, от загрузки ЛВС вычислительной системы и от особенностей реализации промежуточного ПО кластера и может быть для оценочных расчетов принято находящимся в диапазоне от 1 до 50.
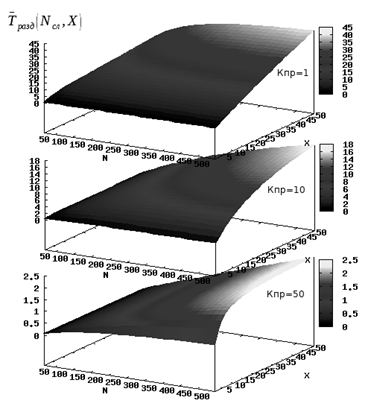
Сравнительная характеристика параллельного и последовательного методов
Из оценочных расчетов можно сделать вывод о высокой эффективности программно-аппаратного комплекса при решении обозначенного круга задач при невысокой и средней нагрузке на сеть. При этом эффективность комплекса тем выше, чем больше суммарное число ядер машин комплекса. Также следует отметить, что если в разработанном алгоритме время обработки данных ниже, соизмеримо или максимум на два порядка выше времени пересылки данных, то применение описанного программно-аппаратного комплекса для решения задач гидро- и газовой динамики себя полностью оправдывает, учитывая доступность средств его построения и относительную простоту пуско-наладочных работ. Если справедливо обратное, то применение таких алгоритмов на данном комплексе нецелесообразно.
Список литературы
1. Белоцерковский О.М., Давыдов Ю.М. Метод крупных частиц в газовой динамике, М.: Наука, 1982.—312 с.
2. http://parallel.ru.